Felix (Ver 0.2 released on Aug 23, 2011!)
Felix is a relational optimizer for statistical inference; it has Tuffy inside.
Check out our new demos built with Felix!
Recent years have seen a surge of sophisticated statistical frameworks with the relational data model (via SQL/logic-like languages). Examples include Markov Logic Networks and Probabilistic Relational Models. While this movement has demonstrated significant quality advantages in numerous applications on small datasets, efficiency and scalability have been a critical challenge to its deployment in Enterprise settings. Felix addresses such performance challenges with an operator-based approach, where each operator performs a statistical algorithm with relational input/output. Felix takes as input standard MLN programs (with some fancy extensions) and solves them in a special way that scales to gigabyte-sized data. Felix 0.2 highlights:
|
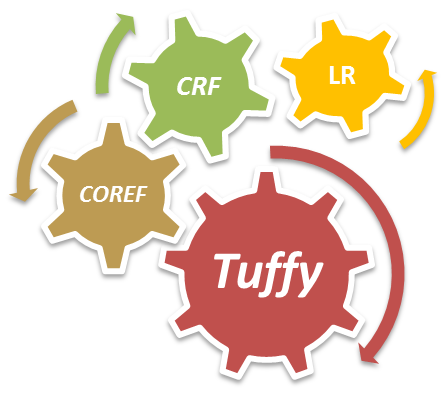
Operator-based Task Decomposition
Felix has a compiler inside to pick out specialized subtasks of the given MLN program. Felix can automatically discover classification, labeling, coreference resolution, and generic MLN inference. These subtasks can then be solved by specialized algorithms, e.g., Logistic Regression, Conditional Random Field, Correlation Clustering, and Tuffy. These decompositions give Felix a significant win on scalability, while the Dual Decomposition framework employed by Felix ensures these decompositions still have consistent semantics in terms of joint inference. |
|
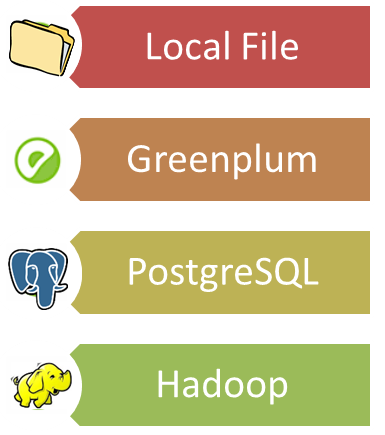
Hybrid Distributed I/O Interface
Felix 0.2 extends the syntax of traditional MLN language and the architecture of Felix 0.1 and Tuffy to work in a more distributed setting. While Felix 0.1 and Tuffy worked on PostgreSQL, Felix 0.2 now supports Greenplum, a distributed RDBMS across multiple nodes, which can deal with a much larger data set. Felix 0.2 also tries to answer the question: "how can our user input gigabyte-sized data sets to Felix?". Felix 0.2 accepts structured input from both local files and relational database tables. Felix 0.2 also integrates a convenient language to translate unstructured and semi-structured data on HDFS into relations readable by Felix. |
|
|
Running on the Web
Felix 0.2 exploits parallelism, both on a single node and cross multiple nodes whenever possisble. Together with the operator-based task decomposition, Felix has been running on 500M documents to extract millions of entities and relations! All these tasks are represented by MLNs and Felix deals with the scalability issues automatically. |
In this prototype implementation of Felix, we take Markov logic as the "unified" language to express sophisticated statistical tasks. Markov logic adds weights to first-order logic rules, and has rigorous semantics based on exponential models. It has been successfully applied to a wide range of applications including information extraction, entity resolution, text mining, and natural language processing. Nevertheless, state-of-the-art implementations of Markov logic (e.g., Alchemy and our own Tuffy) are unaware of the optimization opportunities that motivated Felix, and therefore suffer from suboptimal quality and scalability.
Felix takes as input a Markov logic program (with evidence data) and outputs the same kind of predictions as what Alchemy and Tuffy would output given the same input (if they can run, that is). Internally, Tuffy performs the following steps:
- Compilation: identifies specialized subtasks in the program and assigns them to a predefined set of statistical operators, including logistic regression (LR), conditional random field (CRF), correlation clustering (CC), and Tuffy -- the generic MLN inference engine.
- Optimization: applies cost-based data materialization strategies to ensure the efficiency of data movement between operators.
- Execution: partitions the data with linear programming, so that one operator can process the data in parallel.
For further technical details about Felix, please read our technical report or the documentation page.
Felix is released under the GPL v3 license. You can download the source code with Java doc from the download page.
As part of the ongoing DARPA Machine Reading project, Tuffy is generously supported by the Air Force Research Laboratory (AFRL) under prime contract no. FA8750-09-C-0181, and gifts or research awards from Microsoft, Google, LogicBlox, Johnson Controls, Inc.. Any opinions, findings, and conclusion or recommendations expressed in this work are those of the authors and do not necessarily reflect the views of any of the above sponsors including DARPA, AFRL, or the US government.