| CS245A PROBLEM SET #4 Due by 5pm, Tuesday, February 17, 1998. 4 problems, equal credit. 100 pts. |
| CS245A PROBLEM SET #4 Due by 5pm, Tuesday, February 17, 1998. 4 problems, equal credit. 100 pts. |
Suppose you have 2 relations, R(A, B, C) and S(B, C, D, E). You have a clustered unique (no duplicate keys) B+-tree index on attribute A for relation R. Assume this index is kept entirely in memory (i.e., you do not need to read it from disk).
For relation S, you have two indexes: (i) a non-clustered non-unique B+-tree index for attribute B, and (ii) a clustered non-unique B+-tree index for attribute C. Assume that these two indexes are also kept in memory. Also, assume that all of the tuples of S that agree on attribute C are stored in sequentially adjacent blocks on disk (that is, if more than one block is needed to store all of the tuples with some value of C, then these blocks will be sequentially located on the disk).
Other relevant data:
SELECT * FROM R, S WHERE (R.B=S.B) AND (R.C=S.C)We present you with two query plans:
Plan 1:
For every block BL of R, retrieved using the clustered index on A for R
For every tuple r of BL
Use the index on B for S to retrieve all
of the tuples s of S such that s.B=r.B
For each of these tuples s, if s.C=r.C, output r.A, r.B, r.C,
s.B, s.C, s.D, s.E
Plan 2:
For every block BL of R, retrieved using the clustered index on A for R
For every tuple r of BL
Use the index on C for S to retrieve all
of the tuples s of S such that s.C=r.C
For each of these tuples s, if s.B=r.B, output r.A, r.B, r.C,
s.B, s.C, s.D, s.E
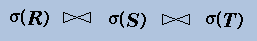
As mentioned in the notes, there are many plans we can construct from this expression, each corresponding to a different join order. Moreover, there are many different algorithms for evaluating a join (e.g., nested loop join, merge sort join, hash join) or a selection (e.g., with or without using an index). That means that each query plan can be evaluated in many different ways, depending on the way each relational operator is executed. We call each such "instantiation" of a query plan a physical query plan.
Assume we can choose between two different ways for doing selections and
between three different join algorithms (we can do one selection one
way, and another selection another way). Also assume that joins are
asymmetric, i.e.,
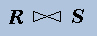 is different from
is different from

Finally, assume that we are only considering left-deep join orders.
What is the number of different physical query plans available for the above relational expression, given our assumptions? Generalize your answer to the case of an expression involving n selections and n-1 joins.
Note that the exact selection predicates are irrelevant, and so are the schemata of the three relations.